Prometheus Monitoring

Introduction to Prometheus Monitoring
Prometheus is a monitoring tool that mainly stores time series of numerical values which are identified by a combination of text based labels. This values can be filtered through its query language called PromQL
NB: Prometheus is not a logging tool since it has no way fo storing lines of log.
PromQL
Prometheus provides a functional query language called PromQL that lets users select and aggregate time series data in real time. The result from these can be consumed by external systems via the HTTP API, or shown as a graph or tabular data.
Through PromQL you can also make alerts through creation of rules. The alerts come in handy whenever you want to test if certain thresholds have been reached. The example below can be used to get the error ratio of an HTTP server:
1
sum (rate(apache_http_response_codes_total[5m]))
Installing Prometheus
You can install prometheus through different ways including:
- As a binary running on your hosts
- As a docker container
To download prometheus you can click on this link and you can run it directly as:
1
2
3
4
5
6
7
8
d3cartel@ASTRID /mnt/c/Users/billyo/prometheus-2.37.5.linux-amd64 ./prometheus
ts=2022-12-20T12:05:02.464Z caller=main.go:491 level=info msg="No time or size retention was set so using the default time retention" duration=15d
ts=2022-12-20T12:05:02.465Z caller=main.go:535 level=info msg="Starting Prometheus Server" mode=server version="(version=2.37.5, branch=HEAD, revision=8d25a0867918173e501b417e7acd85861df8fb0e)"
ts=2022-12-20T12:05:02.465Z caller=main.go:540 level=info build_context="(go=go1.18.9, user=root@fa6380105630, date=20221209-12:46:41)"
[..]
ts=2022-12-20T12:05:02.488Z caller=main.go:1214 level=info msg="Completed loading of configuration file" filename=prometheus.yml totalDuration=2.7315ms db_storage=6.9µs remote_storage=3.1µs web_handler=1.4µs query_engine=2.4µs scrape=1.3801ms scrape_sd=73.6µs notify=59.8µs notify_sd=21.8µs rules=8.5µs tracing=23µs
ts=2022-12-20T12:05:02.488Z caller=main.go:957 level=info msg="Server is ready to receive web requests."
ts=2022-12-20T12:05:02.488Z caller=manager.go:941 level=info component="rule manager" msg="Starting rule manager..."
Navigating to localhost port 9090 you should be able to see something like below:
You can also run it as a docker container by running
1
docker run -p 9090:9090 prom/prometheus
With the docker container we can adapt it to a Kubernetes deployment object that will mount the configuration from a configMap, expose a service and deploy multiple replicas of the same. The easiest way to install prometheus in Kubernetes is by using Helm
To install prometheus in kubernetes cluster we can first add prometheus charts repository to the helm configuration
1
2
3
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo add stable https://charts.helm.sh/stable/
helm repo update
After adding the charts repo we can now install prometheus by running:
1
helm install [RELEASE_NAME] prometheus-community/prometheus
Prometheus Exporters
Some services and applications have their own metrics format and exposition methods and if you are trying to unify your metric pipeline from prometheus to these services and applications, it might be a problem. To solve these the prometheus community is creating and maintaining a big collection of prometheus exporters.
Prometheus exporter is a “translator” program that can collect the server native metrics and re-publish these metrics using the prometheus metrics format.
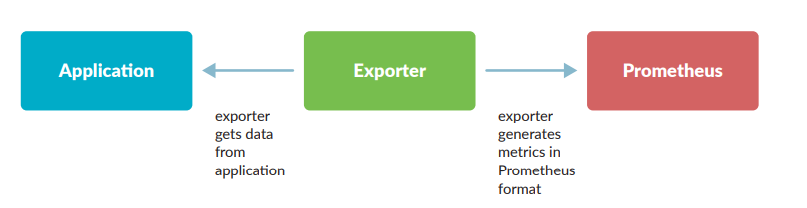
There are a bunch of prometheus exporters on the internat today and you can find more than one exporter for the same application thus when choosing an exporter tou need to correctly identity the application you want to monitor and the metrics you want to get before settling on the exporter to use.
You can use PromCat website to quickly look for exporters you can use.
Installing a Prometheus Exporter
We can use MongoDB exporter as an example here. To install the exporter in a Kubernetes cluster, we will use Helm Chart.
We first create a values.yml file with following parameters.
1
2
3
4
5
6
7
8
fullnameOverride: “mongodb-exporter”
podAnnotations:
prometheus.io/scrape: “true”
prometheus.io/port: “9216”
serviceMonitor:
enabled: false
mongodb:
uri: mongodb://exporter-user:exporter-pass@mongodb:27017
Monitoring Applications
Prometheus Metrics
There are two main paradigms used ro represent the metrics in prometheus:
- dot-metrics
- multi-dimensional tagged metrics
dot-metrics - with dot-metrics, everything you need to know about the metric is contained within the name of the metric. For example
1
2
production.server1.pod1.html.request.total
production.server1.pod1.html.request.error
From the example above you can see the naming of the metrics is hierarchical and separated by dots.
multi-dimensional tagged metrocs - this takes a flat approcah to naming metrics. Here you have a ame combined with a series of labels or tags. Example:
1
<metric name>{<label name>=<label value>, ...}
Prometheus Metrics / OpenMetrics Format
Prometheus metrics text-based format is line oriented. Lines are separated by a line feed character (n) and empty lines are ignored. A metric is composed by several fields:
- Metric name
- Any number of labels, represented as a key-value array
- Current metric value
- Optional metric timestamp
Metric output is typically preceded with # HELP and # TYPE metadata lines. The HELP string identifies the metric name and a brief description of it. The TYPE string identifies the type of metric. If there’s no TYPE before a metric, the metric is set to untyped. Everything else that starts with a # is parsed as a comment.
Prometheus metrics / OpenMetrics represents multi-dimensional data using labels or tags
Prometheus Metrics / OpenMetrics Types
Depending on what kind of information you want to collect, there are four choices you can choose from:
- Counter - this represents a cumulative metric that only increases over time, eg the number of requests to an endpoint.
- Gauge - these are instantaneous measurements of a value. Gauges represent a random value that can increase and decrease randomly, eg load of your system.
- Histogram - This samples observations and counts them in configurable buckets.
- Summary - This samples observations similar to histogram and also gives a total count of observations and a sum of all observed values.
Why use Prometheus for Kubernetes Monitoring
- Service discovery - Targets are periodically scraped by the Prometheus server. Metrics are pulled rather than pushed, thus services and applications are not required to continuously produce data. Several methods can be used by Prometheus servers to automatically find targets for scraping. For instance, you can set up the servers to match and filter container metadata.
- modular and highly available components - Metric collecting, graphic depiction, alerting, and other tasks are handled via composable services. Redundancy and sharding are supported by each of these services.
- Multi-dimensional data model - Similar to how Kubernetes uses labels to organize infrastructure metadata, key-value pairs are used to organize data. This commonality guarantees that Prometheus can gather and analyze time-series data with accuracy.
- Accessible format and protocols - Metrics may be exposed quickly and easily thanks to Prometheus. It makes sure that measurements may be published over a regular HTTP connection and are readable by humans.
Best Practices for Prometheus Monitoring
Choose the best exporter - Choosing the most relevant prometheus exporter can critically affect the success of your kubernetes monitoring strategy.Doing prior research on how the exporter you want to use handles the metrics relevant to your workload will come a long way in making sure you settle on the correct exporter.
Set actionable alerts -A well defined alerting strategy can hep you achieve effective performance monitoring. To achieve this you need to first identify which events or metrics are critical to monitor then set a threshold that can catch issues before the effect can be felt by the end-users. You also need to ensure that the notifications are properly configured to reach appropriate team in a timely manner.
Label carefully - Labeling needs to be done well and in a manner that provides context. A thing to consider is also each label you create consumes resources thus having too many labels can increase your overall resource cots.